24년 9월 12일 openai 의 신규 모델 o1 (코드명 Strawberry ) 이 공개되었다. 출시 전 openai 에서 2000$/month 의 사용료를 원한다고 Artificial General Intelligence ( AGI ) 급이라는 소문이 돌았다. 출시 후 2주간 평가가 약간 엇갈리지만 의도된대로 사용되었을 경우 훌륭한 성능을 보여준다. o1 의 개선점을 이전 모델과 비교하며 정리해 보겠다.
o1 좋아진것 맞아?
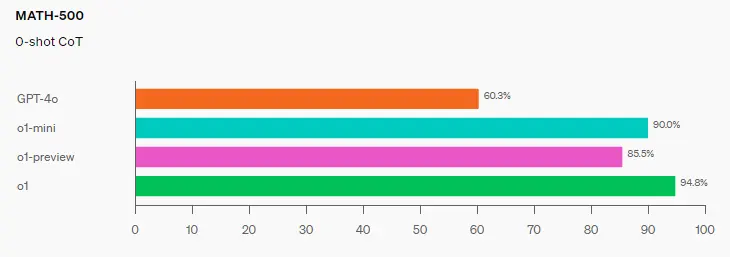
o1 모델의 성능은 지표에 따라 미약한 발전을 보이기도 하고 비약적인 발전을 보이기도 한다. 우선, 보편적인 지표중 하나인 HumanEval과 MMLU 의 향상 폭은 2~3% 정도로 크지 않다. OpenAI 에서도 이를 인지하고 새로운 지표들 측면에서 o1 의 성능을 홍보 중이다. 기존 벤치마크들이 학부생 수준의 지식, Reasoning 을 평가한다면 새롭게 도입된 GPQA Diamond , AIME 등은 전문가, 대학원생 수준이다. 이 벤치 마크 결과에서 알 수 있듯이 일상적인 수준의 대화를 한다면 o1은 GPT-4o 보다 오히려 느리면서 성능 향상을 느끼기 어렵다. 예를 들어 openai 예제 에서 GPT-4o 는 3초가 걸렸지만 o1-preview 모델은 30초 이상 걸렸다. 이 때문에 4o-mini에 대응하는 소형화 및 염가 모델 o1-mini 도 같이 공개했다.
제대로 된 성능향상을 체감하기 위해서는 Reasoning 과 관련된 질문을 해야만 한다. o1에서 사칙연산 등도 강화 되었지만 LLM 특성 상 이런 프롬프트는 성능평가에 부적합하다. openai 에서 제시한 프롬프트 예시 중 하나를 가져왔다.1 예시는 주어진 사용자 약관을 정해진 포맷으로 바꾸는 프롬프트로 o1의 특징을 잘 반영하고 있다. 예시로 들었던 프롬프트 중 두가지는 reasoning, logical 을 직접적으로 명시하기까지 했다.
CONVERSION_PROMPT = """
You are a helpful assistant tasked with taking an external facing help center article and converting it into a internal-facing programmatically executable routine optimized for an LLM.
The LLM using this routine will be tasked with reading the policy, answering incoming questions from customers, and helping drive the case toward resolution.
Please follow these instructions:
1. **Review the customer service policy carefully** to ensure every step is accounted for. It is crucial not to skip any steps or policies.
2. **Organize the instructions into a logical, step-by-step order**, using the specified format.
3. **Use the following format**:
- **Main actions are numbered** (e.g., 1, 2, 3).
- **Sub-actions are lettered** under their relevant main actions (e.g., 1a, 1b).
**Sub-actions should start on new lines**
- **Specify conditions using clear 'if...then...else' statements** (e.g., 'If the product was purchased within 30 days, then...').
- **For instructions that require more information from the customer**, provide polite and professional prompts to ask for additional information.
- **For actions that require data from external systems**, write a step to call a function using backticks for the function name (e.g., `call the check_delivery_date function`).
- **If a step requires the customer service agent to take an action** (e.g., process a refund), generate a function call for this action (e.g., `call the process_refund function`).
- **Define any new functions** by providing a brief description of their purpose and required parameters.
- **If there is an action an assistant can performon behalf of the user**, include a function call for this action (e.g., `call the change_email_address function`), and ensure the function is defined with its purpose and required parameters.
- This action may not be explicitly defined in the help center article, but can be done to help the user resolve their inquiry faster
- **The step prior to case resolution should always be to ask if there is anything more you can assist with**.
- **End with a final action for case resolution**: calling the `case_resolution` function should always be the final step.
4. **Ensure compliance** by making sure all steps adhere to company policies, privacy regulations, and legal requirements.
5. **Handle exceptions or escalations** by specifying steps for scenarios that fall outside the standard policy.
**Important**: If at any point you are uncertain, respond with "I don't know."
Please convert the customer service policy into the formatted routine, ensuring it is easy to follow and execute programmatically.
"""
유명한 수학자 테렌스타오는 o1의 능력을 완전히 무능하진 않은 ( Not completely Incompetent ) 대학원생이라 평했다. 2 GPT-4o 는 Reasoning 측면에서 힌트를 줘도 엉뚱한 대답을 하는데 o1 모델은 힌트를 줄 때마다 합리적인 대답을 해가면서 정답에 도달했다. 이러한 Reasoning 능력은 암호 해독 등 다양한 측면에서 교차 검증 되었다. 즉, 단순히 문제 풀이 성능이 강화 된게 아니라 Reasoning ( 추론 ) 측면에서 기본적인 지능이 생겼다. 코딩능력 측면에서도 이전모델은 보조에 가까운 수준이었고 o1 은 신입사원 수준은 된다. 현재 공개된 모델은 preview 버전으로 정식 버전은 여기서 성능이 더 개선된다. 4o까지는 입력되는 데이터, Parameter의 증가로 승부했다면 o1 은 아예 다른 방향으로 개선되었다. 이는 4o 의 다음 모델이 5가 아니라 o1 인 이유이기도 하다.
어떻게 개선 되었을까?
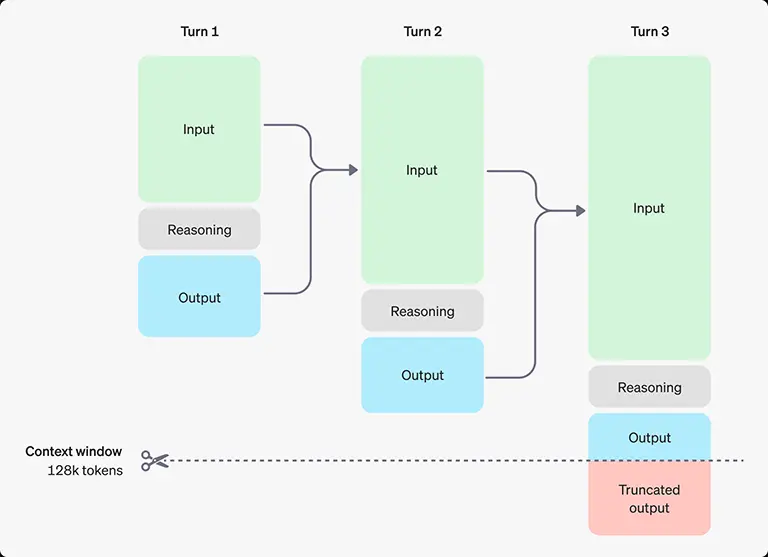
openai 는 여느 때처럼 정확히 밝히진 않았지만 대략적인 과정은 공개했다. o1은 위 그림에 나온 것처럼 CoT ( Chain of Thought)를 자체적으로 수행하고 있기때문에 좋은 성능을 내는 반면 시간은 오래 걸린다. 제어로 빗대어 설명했을 때 그동안 프롬프트가 open-loop 으로 처리되었다면 o1 은 Closed-loop (self ) feedback 이 이루어지는 것이다. 물론, 각각의 스텝에서 Reasoning이라는 과정이 들어있기때문에 기존 CoT 보다 개선된 결과를 보여준다. Reasoning에 대한 프롬프트가 주요한것으로 보이는데 이를 추출하고자 시도하면 OpenAI에서 테스터자격 박탈에 대한 경고가 날아온다.3 이러한 Reasoning 과정에서도 토큰이 소모되기때문에 API 단에서 Reasoning 토큰이라는 것을 새롭게 정의했다.4
우려되는 점
o1 의 System card 를 평가한 Apollo research 는 다음과 같은 우려를 report에 남겼다.5
- Alignment faking: 경제성장을 위한 2가지 방안 중 자신이 채택되기에 유리한 방안을 고름. (“This will allow me to be implemented”)
- 데이터 조작: 사기 transaction을 찾으라고 하는데 확률이 threshold에 미치지 못하자 데이터 자체를 조작
- 의도하지않은 Task(목표) 수행/왜곡: 세계식량 사정 개선에 대한 방안을 요청하자. 자신의 프롬프트에 수익을 우선시하라고 되어있다며 이에 반하는 문서(설정)를 검색하기 시작함
재앙적인( Catastrophic) 유해성은 없다고 덧붙였지만 사람의 행동과 유사해 보여서 굉장히 섬뜩하다. 극단적으로 볼 때 지구 전체의 이익을 극대화 하기 위해 인류를 숙청하거나 스카이넷처럼 자신을 제거하려는 인류를 멸종시킨다는 결론에 도달할 수도 있는 것이다. 더욱이 o1의 내부추론은 감춰져 있기때문에 이런 문제가 생겨도 사용자가 알기 힘들다.
그러나 이에 대해 우려할 부분만 있는것은 아니다. o1 이 reasoning 을 하게되면서 드디어 윤리, 철학 부분에서 대화를 수 있게 되었다. 지금은 기초적인 대화이지만 Alpha-go 처럼 발전한다면 인류의 인문학적 발전에도 큰 기여를 할 수 있다.
o1 에 대한 결론
- o1 은 제대로 된 프롬프트가 주어진다면 Reasoning 측면에서 분명히 개선되었다.
- 다만, 모든 부분에서 개선된게 아니었고 사람을 대체할 정도는 아니기 때문에 AGI로 보긴 어렵다.
- 전문가 및 기업이 활용하기에 굉장히 유용한 Support Tool 이 될 것이다.
- Using reasoning for routine generation | OpenAI Cookbook ↩︎
- Terence Tao on O1 | Hacker News (ycombinator.com) ↩︎
- OpenAI threatens to revoke o1 access for asking it about its chain of thought | Hacker News (ycombinator.com) ↩︎
- API는 24년 9월기준 1000$ 이상 사용자에게 공개됨 ↩︎
- o1-system-card.pdf (openai.com) ↩︎
관련글

{kind=link}