주가 예측 서론
회사에서 주가 예측 과 관련된 코딩 공모전을 열었다.
제대로 인공신경망 모델을 만들기 위해서는
설계, 튜닝에 상당한 시간을 투자해야한다.
현생이 바쁘기 때문에 순위는 일찌감치 포기했다.
다만 구현 난이도가 궁금해서 인터넷 상 코드를 테스트해 보았다.
Github 가 보편화된 이후로 코딩 실력은 필요한 코드를
얼마나 빠르게 찾아 응용할 수 있는지에 달렸다.
다행히 주가 예측 에 대한 코드는 인터넷에 차고 넘친다.
코드 선택 기준
- Tensorflow 로 작성될 것
- VM에서 학습 가능한 복잡도
- 논문 수준의 분석, 설계 필요없음
- 20년도 이후 비교적 최신 코드
많은 코드들 중에 위 조건에 해당하는 코드를 탐색했다.
주가 예측에는 보편적으로 LSTM , GRU , ARIMA 등이 사용되는데
데이터셋의 종류, 형태에 따라 성능이 달라진다.
그리고 LSTM + GRU , LSTM + ARIMA , ARIMA + GRU 처럼
하이브리드로 구성될 때 성능이 향상된다.
이중에서 LSTM + GRU 에 해당하는 코드들을 찾아봤다.
둘 다 RNN이기때문에 hybrid 로 만들기 쉽고
tensorflow 로 구현하기도 쉽다.
Kaggle 원본 코드는 링크로 첨부하니 참고하길 바란다.
본론
모듈 및 데이터 임포트
코드에서 사용되는 모듈들과 설명
- pandas : CSV를 사용하기 쉬운 dataframe , series로 변환,저장
- numpy : 데이터 가공
- sklearn : 학습에 필요한 utility 제공
- tensorflow : 실질적으로 학습을 진행
- matplotlib : plot 에 사용
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
import os
os.environ['TF_ENABLE_ONEDNN_OPTS']='0'
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.layers import LSTM, GRU
from keras.callbacks import EarlyStopping,ModelCheckpoint
from sklearn.preprocessing import MinMaxScaler
#import data
org_df={}
dflist=['AAPL','AMD','ATVI','CSCO','EBAY','GOOGL','INTC','MSFT','MU','NTGR','NVDA','SBUX','STX','TSM','WDC']
for i in range(1,16):
org_df[i]=pd.read_csv(f"/dataset/{dflist[i-1]}.csv")
전처리
우선 데이터를 별도로 어떻게 전처리 할것인지 정해야 한다.
sklearn 에서 제공하는 MinMaxScaler 를 사용해
0에서 1 사이의 값을 가지도록 정규화 했다.
데이터의 노이즈가 심하지 않아 필터는 적용하지않았다.
data는 6개의 column을 가지는데 원본 저자는 종가만 학습에 사용했다.
다른 데이터로 accuracy를 올릴 수도 있지만 학습,튜닝에 오랜시간이 걸린다.
또한 volume을 제외한 column 들은 종가와 유사하기때문에
accuracy를 올리는데 효율적이지 못하다.
단순하게 k개의 사전데이터로 다음 날을 예측하도록 input을 구성했다.
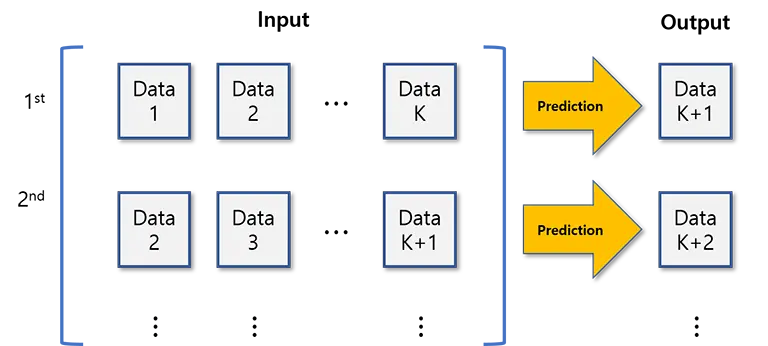

따라서 위 그림 대로 Input 과 Output 데이터를 가공한다.
train set과 validation set을 나누어주기 위해서는 train_test_split을 사용하거나
model.fit에서 validation_split 옵션을 사용하면 된다.
def create_dataset(dataset, time_step=1):
dataX, dataY = [], []
for i in range(len(dataset)-time_step-1):
a = dataset[i:(i+time_step)]
dataX.append(a)
dataY.append(dataset[i + time_step])
return np.array(dataX), np.array(dataY)
t_step=10
scaler=MinMaxScaler(feature_range=(0,1))
scaled=scaler.fit_transform(np.array(org_df[1]['Close']).reshape(-1,1))
X_train,y_train=create_dataset(scaled,t_step)
# X_train,X_val,y_train,y_val=train_test_split(X_train,y_train,test_size=0.3,random_state=0)
신경망 구축 및 학습
def custom_loss(y_true, y_pred):
mae = tf.keras.losses.MeanAbsoluteError()
return mae(y_true, y_pred)/np.mean(abs(y_true))
callbacks = [EarlyStopping(monitor='val_loss',
patience=15,min_delta=0.01),
ModelCheckpoint(filepath='best_model.h5',
monitor='val_loss',
save_best_only=True, restore_best_weights=True)]
model=Sequential()
model.add(LSTM(32,return_sequences=True,input_shape=(t_step,1)))
model.add(LSTM(32,return_sequences=True))
model.add(Dropout(0.2))
model.add(GRU(32,return_sequences=True))
model.add(Dropout(0.2))
model.add(GRU(32,return_sequences=True))
model.add(GRU(32))
model.add(Dropout(0.2))
model.add(Dense(1))
model.compile(loss=custom_loss,optimizer='adam' , metrics = [ "mae",'mse'],run_eagerly=True)
model.summary()
history=model.fit(X_train,y_train,validation_split=0.3,epochs=100,batch_size=64,verbose=0,callbacks=callbacks)
# history=model.fit(X_train,y_train,validation_data=(X_val,y_val),epochs=100,batch_size=64,verbose=1,callbacks=callbacks)
print('done')
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_12 (LSTM) (None, 10, 32) 4352
lstm_13 (LSTM) (None, 10, 32) 8320
dropout_18 (Dropout) (None, 10, 32) 0
gru_18 (GRU) (None, 10, 32) 6336
dropout_19 (Dropout) (None, 10, 32) 0
gru_19 (GRU) (None, 10, 32) 6336
gru_20 (GRU) (None, 32) 6336
dropout_20 (Dropout) (None, 32) 0
dense_6 (Dense) (None, 1) 33
=================================================================
LSTM과 GRU가 같이 배치된 하이브리드 모델이다.
학습의 속도, accuracy는 모델의 배치,shape에도 크게 영향 받으나 절대적인 법칙은 없다.
성능을 보면서 적절하게 변경하면 된다.
원본 코드와 다르게 레이어를 배치해 봤지만 원본대로 하는게 가장 정확도가 높다.
loss는 mse, mae 등 여러가지를 사용할 수 있는데 코드에 나온것처럼
새로운 loss function을 정의해도 된다.
물론, mae와 mse 를 섞는 등 다른 평가 요소를 사용하여 성능을 더 개선할 수 있다.
코드수행에 생각보다 시간이 걸리는데 EarlyStopping callback을 통해
학습을 조기 중단시킬 수 있다.
혹은 processpool executor를 사용하여 수행속도를 올릴 수 있다.
마지막으로 model.fit을 통해 학습을 수행하는데
epochs, batch_size 등 각종 parameter의 튜닝이 필요하다.
이러한 hyper parameter는 keras의 tuner를 사용해도 되고
단순한 반복문을 만들어 기록해도 된다.
verbose를 1로 두면 학습 과정을 지켜볼 수 있습니다.
epoch별 loss값을 지켜보면 학습이 정상진행되는지 알 수 있기때문에 신경망을 설계할 때 유용하다.
다음 코드를 통해 학습이 잘됐는지 plot해보자.
hh=history.history epochs=range(len(hh['loss'])) plt.plot(epochs,hh['loss'],label='loss') plt.plot(epochs,hh['val_loss'],label='val_loss') plt.legend() plt.show()
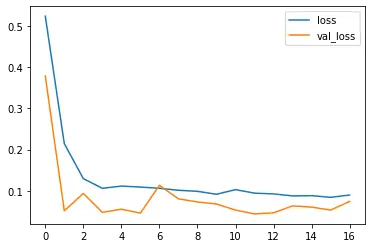

loss와 validation_loss가 둘 다 수렴하고 있으므로
학습이 어느정도 잘 이루어지고 있다.
과적합이 일어난다면 신경망의 설계,변수를 바꾸거나
정규화를 변경함으로써 해결할 수 있다.
주가 예측 값 도출
prd={}
nmae={}
day_to_predict=7
for _,i in enumerate(org_df):
last_data=scaler[i].fit_transform(np.array(org_df[i]['Close'].iloc[-t_step:]).reshape(-1,1))
prd_list=[]
for j in range(day_to_predict):
last_data=last_data[-t_step:]
prd_temp=models[i].predict(np.array(last_data).reshape(1,t_step[i],1),verbose=0)
prd_list.append(prd_temp[0][0])
last_data=np.append(last_data,pd.Series(prd_temp[0][0]))
prd[i]=scaler[i].inverse_transform(np.array(prd_list).reshape(-1,1))[:,0]
nmae[i]=my_loss(test_df[i]['Close'][:7],prd[i])
print(f'{dflist[i-1]} : {nmae[i]}')
print(f'avg={pd.Series(nmae).mean()}')
이제 위 코드를 통해 주가 예측 데이터를 도출한다.
루틴을 간단하게 설명하면 다음과 같습니다.
- 마지막 k개의 데이터를 input으로 만든다.
- input을 통해 다음날의 데이터를 예측한다.
- 예측 데이터를 input 데이터에 덧붙인다.
위 과정을 예측하고 싶은만큼 날만큼 반복하여 loss값을 기록한다.
기록된 loss값이나 평균 loss값으로 학습이 잘 이루어졌는지 확인 가능하다.
주가 예측 결론
AAPL : 0.04620344564318657 AMD : 0.11094651371240616 ATVI : 0.0061081573367118835 CSCO : 0.01842576451599598 EBAY : 0.026052556931972504 GOOGL : 0.03204019367694855 INTC : 0.03417059779167175 MSFT : 0.05612574890255928 MU : 0.008338606916368008 NTGR : 0.02389097958803177 NVDA : 0.0929316058754921 SBUX : 0.015276948921382427 STX : 0.07766019552946091 TSM : 0.02993595041334629 WDC : 0.03140253946185112 avg = 0.04063398440678914
- 평균 오차: 주가의 4~5%
- 소요시간: 코딩 30분 + 학습 30분 (CPU,싱글 코어 기준)
약간의 튜닝으로도 성능을 2~3%까지 개선할 수 있다.
30분짜리 코딩치고 주가 예측 결과가 나쁘지 않다.
강화학습, deep learning 등에서 이론 공부만으로 시간을 버리는 경우가 많다.
Matlab의 Tuner/Optimizer를 쓰면서 알고리즘을 다 이해하는건 아니듯이
알고리즘 이해에 너무 긴 시간을 쏟을 필요 없다.
차라리 kaggle 등에서 실용적인 코드를 찾아 직접 해보는것이 도움이 된다.
여러분들께도 올려드린 코드가 도움이 되길 바란다.